这里想验证的一个想法是,能否做美术资源的持续集成(CI)。 当然业界是有这样实践的,这里想自己搭遍框架。
涉及到版本发布的业务,比如app开发,引擎开发,应用开发等等,一般都会做CI,方便快速迭代。游戏影视行业亦有如此的需求。最常见的是游戏打包了。
不过,作为游戏TA/TD,我们更关心的是,美术资产生命周期上的质量保证。CI在美术工作流程上的意义,可以在于减少手动操作,更快看到最终效果。
如同在前面一篇Char Pipeline中讨论的,本文尝试了美术流程中一个最简单的步骤作为示例:
检查面数,生成LOD。
我们的目标是,搭建一个CI框架
- 方便扩展写blender中的单元脚本,单元脚本用来做单元测试(这里是检查面数)或者单元build(这里是生成lod)
- 使用docker运行blender,提高扩展性
- 部署成Jenkins CI,使其有UI界面,并能自动触发build
单就做LOD这件事,有很多种不同的方法
- 1 美术在自己机器上生成LOD,设置距离等。
- 2 导入引擎时自动生成
- 3 服务器上dailybuild
每个方案都有不同的具体解决方案,比如服务器build可以用simplygon sdk, houdini等等。
而面数检查这件事,同样有很多不同的方法
- 1 美术手动检查
- 2 美术在本机上检查
- 3 美术在提交前自动检查
- 4 服务器上自动检查
方案总有取舍,这里不讨论推荐读者使用哪种。这里仅仅尝试一种自己以前没见过但想过的方案,作为实验和proof of concept.
以下首先介绍一些我们会使用到的工具
1. CI工具与Jenkins
CI的一个典型pipeline是:
- 自动执行git/svn拉取,
- 调用cmd/shell/powershell进行自动化操作,比如打包
- 发布,比如开启服务器,上传apk包,git push之类
可以使用UI配置每一个步骤,也可以写成一个描述文件。
一个典型的pipeline dashboard,可以看到每次build中每个步骤是否成功和耗时时间。
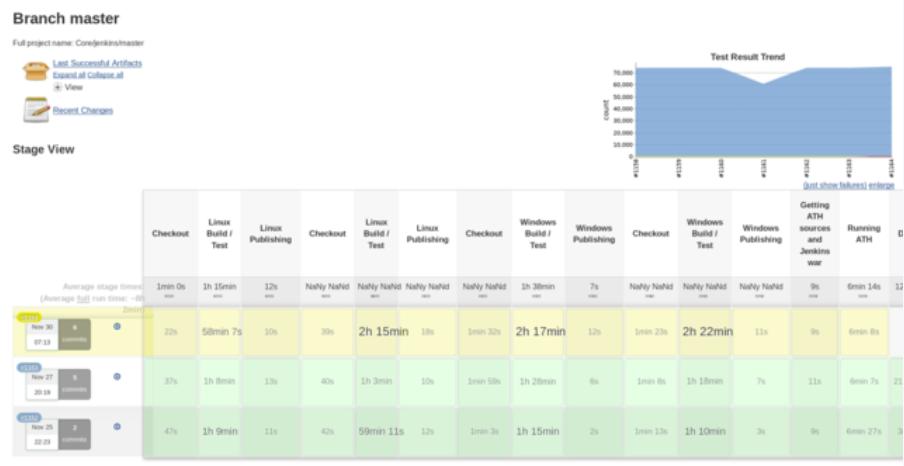
CI工具做的事情也就是配置,执行,可视化这些pipeline。
CI工具有很多,比如:
Jenkins
TeamCity
GitLab CI/CD
CircleCI
Travis CI
Drone CI
这里笔者也没多做研究,毕竟Jenkins是市场占有率最高,插件最多,而且还免费的工具。
Jenkins是一个java写的服务器,可以安装在本地或者服务器,然后用浏览器访问host的8080端口就能看到UI。安装和使用都还挺用户友好。
学习jenkins直接看官方文档就很有帮助,大概几个小时就能入门吧。
一个很有帮助的是将怎么写Jenkinsfile,也就是pipeline配置,的教程
https://www.jenkins.io/ doc/book/pipeline/jenkinsfile/
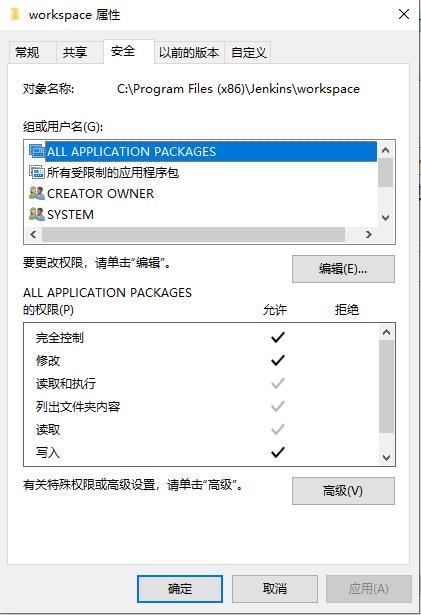
遇到的一个坑是,jenkins进程可能对目标目录没有访问权限,比如写入文件时提示permission denied
解决方法是修改目标目录的权限,改为完全控制,如下图
https://github.com/docker/for-win/issues/3385
那么笔者这个实验中,是否是必须要使用Jenkins的?
当然不是,可以自己写脚本触发build和可视化。
Jenkinsfile会被翻译成jvm虚拟机的groovy语言执行。在其中可以做比如调用shell,错误捕获,邮件通知等等操作。更有很多插件提供了不一样的功能。
所以这个配置文件也就是被翻译成代码的,和自己写python一样的。
不过,既然有jenkins这个轮子为何不用。BlueOcean插件的可视化确实做的不错哦。
2. Docker和容器化
“Docker 是一个开源的应用容器引擎”,一般第一句介绍是这样的。
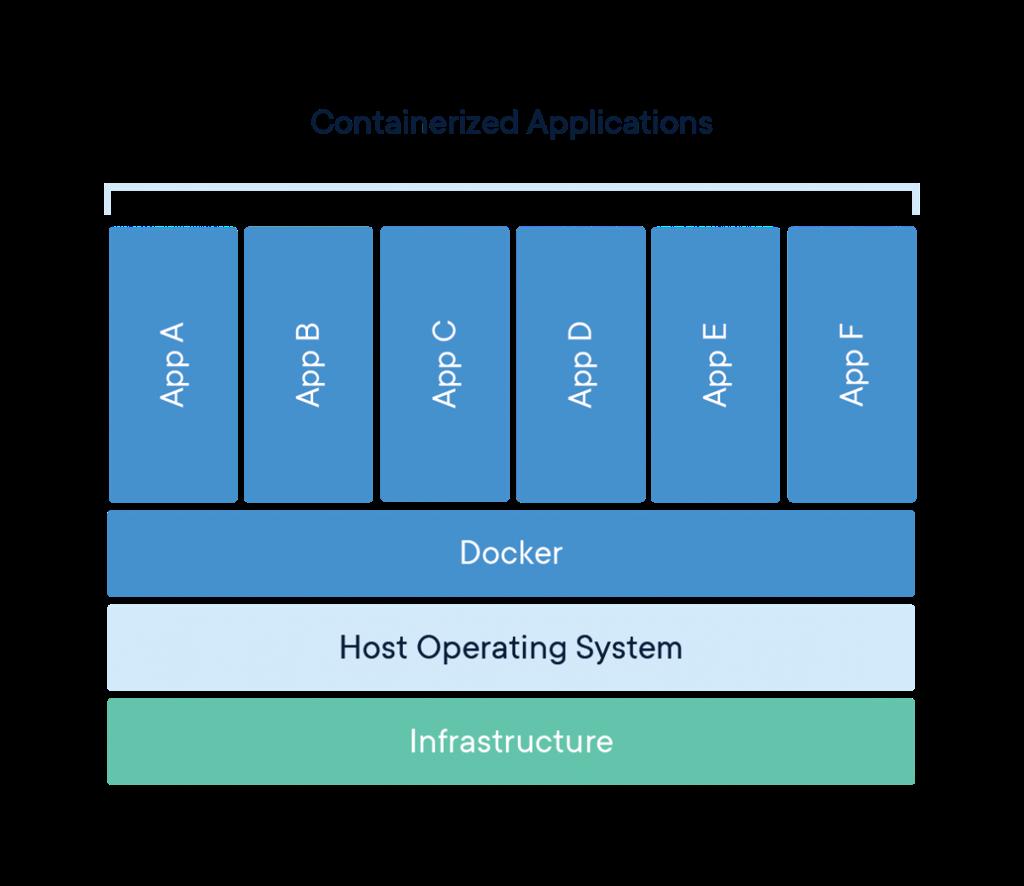
通俗理解,docker是一个可以运行程序的环境,这个环境与外部隔离。就像一个虚拟机沙盒一样。比如在本机上安装了python3.6, docker里装了python3.8,那么docker里运行程序的时候,不会受到本机python3.6的影响。
当然就python的例子中,它和virtualenv的效果是一样的。不同的是,docker的虚拟化更加底层,利用的是linux操作系统的namespace功能做隔离,而virtualenv是应用层的隔离,不过就是设了不同的路径。另外,docker的部署非常简单。直接docker pull image一个指令就能下载下来一个可运行的环境。
直接的好处是,配置复杂的安装环境,可以很容易制作一个docker image,快速安装和部署。另一个好处是,docker可以方便扩容。配合k8s伸缩,快速将docker运行在多台服务器上。
这么笔者这个实验中,是否是必须要使用docker的?
也不是必须,可以直接命令行调用本机安装的软件执行。不过这样没有docker好部署,也就是不好把这个服务扩容,放到第二台电脑上。
虽然docker使用linux系统的,但在当前windows上,得益于WSL这个功能的存在,也是能用docker的,直接安装一个docker desktop for windows就行了
比如运行
1 | docker run -it --rm -v ${pwd}:/media/ nytimes/blender |
没有下载这个docker image的话会自动下载。下载完毕后会进入这个image的命令行。
这里,-it参数代表进入docker后可以输入命令行。
–rm代表完成后自动关闭docker
-v ${pwd}:/media/ 代表,将当前工作目录挂在在docker的/media目录下面。这样,在docker里就可以访问当前工作目录下的资源
最后nytimes/blender是一个镜像的名字,这是nytimes做个一个blender docker image,其中安装了blender.
进入docker命令行后,就可以和blender命令行模式一样调用了
比如这样,运行一个test.py
1 | blender --background -p test.py |
3. Blender中减面和面数统计
笔者这里使用blender命令行模式生成LOD,具体来说是给模型添加一个Decimate修改器减面。
当然,这有很多不完备的事情,比如不像simplygon一样有很多选项。
也有其他方法,比如用houdini engine,比如直接用simplygon sdk, 甚至用unity editor,只要是能命令行执行就可以。
笔者这里之所以用blender,主要是因为它开源。。。所以好放github咯。
所以核心的代码就很简单,添加减面修改器并塌陷
1 | def reduce_mesh(obj, perct): |
对于面数统计,我们拿到mesh的polygons数据,计算下长度就行了
1 | def get_polycount(obj): |
4. 用decorator和反射机制和简化和复用blender代码
这里抽象的一个问题是
- 如何抽象共用部分,使得单元脚本写起来更简单。
- 当有很多脚本时,如何泛型一起调用它们。
对第一个问题。
比如,单元脚本共同需要做的一件事是获得参数,并在fbx中导入模型,这就很方便使用decorator这个功能
decorator就是一个函数wrapper,可以在被装饰的函数调用前后添加一些功能。
1 | def our_decorator(func): |
https://www.python-course.eu/python3_decorators.php
我们想做的无非就是
1 | def blender_fbx_test(func): |
在单元测试和build前解析参数和导入模型
这样,单元测试和build脚本写起来就很简单了,如下格式就好
1 | import bpy |
1 | import bpy |
这样还有个好处是它不需要我们CI环境也就直接能在blender界面跑起来,不会有多余的无法执行代码。
对第二个问题,我们希望的是能够通过py文件名直接执行,这样blender运行时直接
1 | blender --background -P media/bpy_runner.py --script $script_path |
将脚本名作为参数直接传给runner运行。
这里之所以不直接用脚本py执行,而封装一个runner,是因为没找到太好运行docker后执行自定义带参数sh的方法,这样docker里volume mount到非根目录下会有需要添加PATH的操作,不想在单元脚本里写。
这里反射的意思是,通过模块或者函数字符串名称,调用函数
这就需要用python的inspect,importlib等模块通过文件名加载,查找meta数据如函数名和参数列表等等
比如下面就通过路径加载了一个单元脚本
1 | spec = importlib.util.spec_from_file_location("bpy_script", script_path) |
5 组装起来
这个简易的pipeline分成四步,
第一步collect,收集所有需要生成lod的模型,写一个manifest
第二步test,收集所有单元测试脚本,根据manifest逐个统计,这里是统计面数
第二步build,收集所有单元build脚本,根据manifest逐个统计,这里是生成lod
第三步submit,提交

那么我们写一个Jenkinsfile,作为pipeline配置
十分清晰明了,每一步执行一个powershell脚本。
其中test和build步骤可以做异常捕捉,出了错就设成unstable
1 | pipeline { |
每一步也都很简单,比如collect.ps1
1 | docker run --rm -v ${pwd}:/media/ python:3 python media/scripts/collect_manifest.py -d 'media/' |
就是运行一个python的docker,执行一个collect_manifest.py
比如第二步tests.ps1
1 | $files = Get-Content .geomanifest.json | ConvertFrom-Json |
我们做的就是,遍历所有模型和测试脚本,然后通过一个blender docker调用检查
在jenkins中创建一个pipeline项目,在pipeline tab中添加一个pipeline script from scm,然后scriptpath填写Jenkinsfile,保存,就可以执行了。
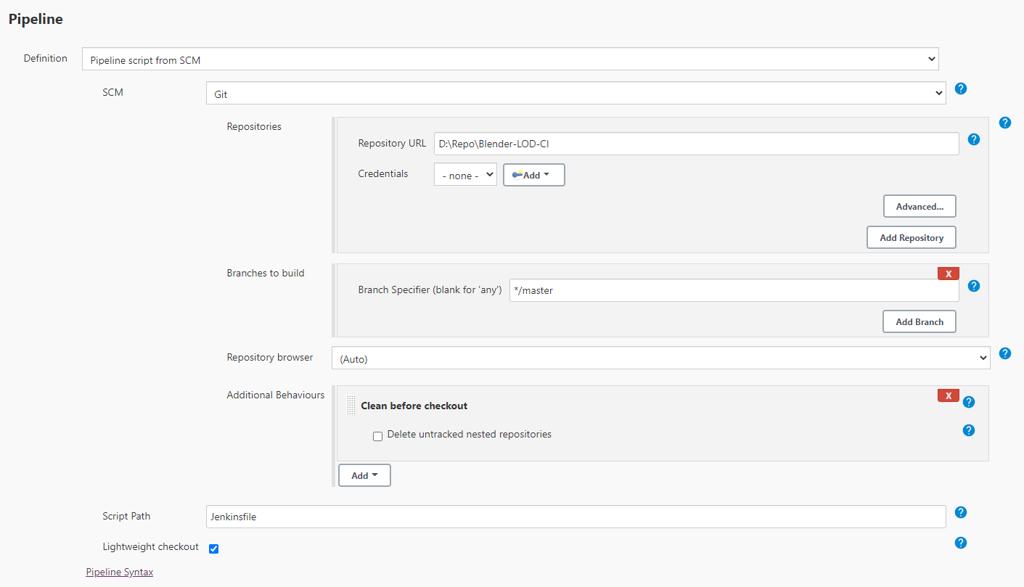
直接自带一个dashboard可视化
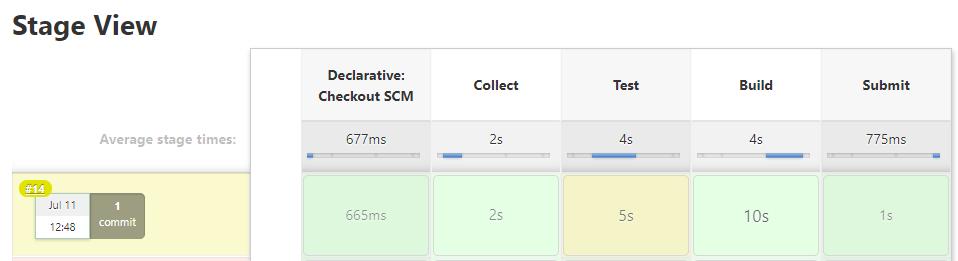
6. 讨论,什么是pipeline?
在Jenkins中,pipeline就是系列步骤,可能在做测试,做build等等。
但在游戏美术中,pipeline涵盖的东西太广了,笔者最近才开始理解,Pipeline TD可能是在干什么,什么是工具链。
笔者自己的解释是,美术资源从一无所有到进入游戏版本,其中会遇到很多问题,比如
- 美术需要用多个DCC工作,怎么保证不同软件/不同用户之间方便数据同步
- 美术在某个DCC中需要花很多时间操作,怎么减少这些操作时间
- 美术资源需要很多步骤才能进入引擎,怎么加快这个过程
- 美术资源制作中可能会产生错误,怎么减少这些错误
- 美术资源在引擎中会有预算问题,怎么防止渲染和内存预算超标
- 怎样方便review
具体到不同资源的制作,比如角色,植物,场景道具,建筑,载具,枪支,都会有特殊的地方。但是总归有一些共性的问题,据一些例子就是上面列出的这些。 怎么解决这些问题,就是pipeline TD做的工作。
相对来说,jenkins还是相对简单的一个pipeline,而且它每一步都可以自动操作。
但在传统游戏开发流程中呢?美术资源制作的大部分步骤,都是需要手动操作的。一方面是因为自动生成的质量太差,一方面是没有这个自动运维的意识,再有一方面是经常有特殊的需求。
也就因此,很多时候感觉是在做人肉运维,手动梳理制作中遇到的问题。还有很多时候,感觉像是一个管理岗位,需要对接很多人。
除了需要PM管理外,TD需要从技术角度对团队协作,需求沟通,交付质量负责。
写工具是提升交付质量和节省时间的自救方法。
我们回顾一下软件工程和devops的经验,怎样保证质量?怎样保证交付?
- 控制需求
- 迭代反馈
- 自动用例测试
- 持续集成
当然,单在某个方面制作procedural工具是很酷很重要的事情。但从运维的角度看,需要的是一套框架,而不仅仅是一个工具。
回到美术pipeline的讨论中,为什么要尝试在做资源的CI?这个实验有什么意义?
当然,这不是最好的方式,很多时候也没有必要。
一般制作时步骤很多,比如从概念,到高模,低模,uv,贴图,整合。这里仅仅是用最简单的一个步骤做实验。
这里讨论,只是把它作为一种方案摆出来。对于数据量大,对美术透明的资产操作,放到服务器做CI是一个思路。
主要希望还是能提高交付质量,提高迭代速度,简化人工操作,减少bug。
影视行业中使用渲染农场就是一个常见的服务器CI方式,当然可以采用。但是当下云计算资源逐渐普及的情况下,使用虚拟主机做服务器CI也会更加普遍。
欢迎讨论。