Houdini PDG是17.5版本新增的一个任务管理模式,方便最终结果的分步生成。
笔者当前使用的17.5.258版本,鉴于这个功能刚刚出现,目前似乎是还有些bug,其后的版本可能会修复的。
到目前为止(~2019.6,确实没看到什么houdini engine + pdg的教程,只有Kenny Lammer的一套PDG for Indie Game Dev。
https://www.indie-pixel.com/unityCourses/PDG-for-Indie-Game-Development
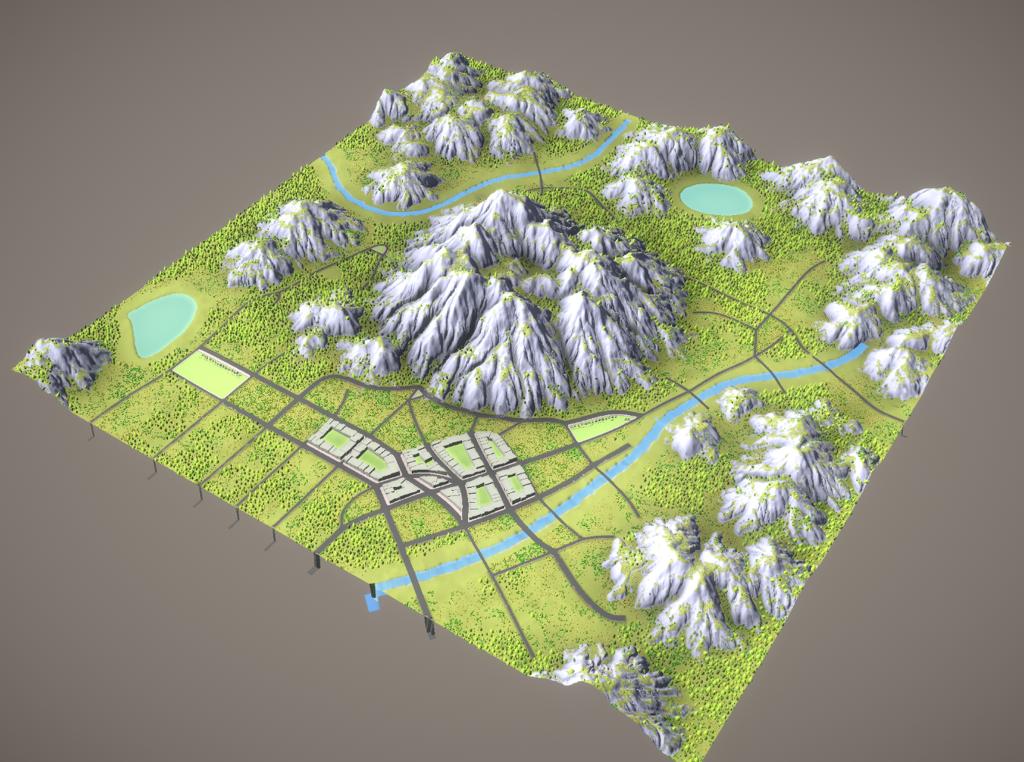
笔者尝试将之前道路生成,地块生成文章整合进一个PDG,生成一个小的城市,体验一下PDG的使用。那自然是有很多坑。
个人感觉PDG的主要优势:
显式化分步操作,方便每步参数调整,避免整体生成时间过长。
多线程生成,PDG中有一个任务调度器,自动根据依赖关系给空闲CPU指派workitem。
方便程序互操作,可以调度maya/p4v等等,其实用以前可以py自己写,这次显式地增加了这个功能。
但目前还有个问题是Dirty模式有点奇怪或者有bug,你永远不知道一个节点是否recook,用了哪次生成的cache。
分布操作这个事情,其实以前很多用户都有这种操作习惯:前一步生成文件cache起来存在硬盘上,比如粒子/物理渲染的逐帧模型,然后直接从文件读取cache进行下一步操作。PDG封装了这个模式,每一个HDAProcessor都会自动缓存文件并交给下一步操作,使得整个程序是流程更自动化。
多线程呢是比较好用的,但问题是为什么需要那么多的同样种类不同参数的资源?就算生成了,游戏里为了资源优化考虑,也没必要这么多变化,倒是可以理解成方便挑选参数,从参数空间中多生成一些,人肉梯度下降,从这个意义上讲,可以一定程度上提高生成资源的质量。另一个问题是,多线程不会导致生成时间倍数缩短,比如terrain分成四块处理,笔者的感觉也就每块提高了1倍的速度。并且还有线程调度和开销和cache存储的开销,每个item都会有常量时间的浪费。
对于游戏开发为什么需要PDG?
个人感觉还是indie小团队的场景生成比较需要。当前版本的houdini engine在unity内的交互实在是难受,大厂可能会有自家的引擎或者编辑器,并且有人力开发引擎内与houdini交互的组件。至于HDA的任务调度?在引擎内做其实也可以啊,有钱就多加点build机好了。而与maya/p4v互操作呢,引擎里一般都集成了。
所以也就是对没有精力重写引擎与houdini交互的小厂开发者,使用houdini engine + PDG会方便很多。
一些Houdini Engine的注意:
1. Workitem与Input
一个HDA可能有1~9999个input
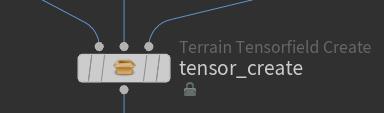
一个HDA Processor只有一个Input,但是可以有多个work item(绿色的点)
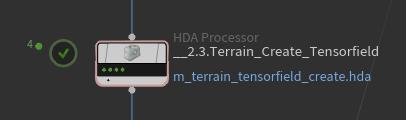
一个work item执行一次HDA,因此如果一个HDA需要3个input,那么每个work item都需要3个input
那么问题来了,当前work item的input怎么对应前面的哪个work item?
如果前面workitem数量都一致,很好办,用partition by index。
但是当前HDA Processor的输入的work item数量可能不一致,怎么办?
如果只有2个input,partition by index的模式中secondary input打成all就行,但是3个input就挂了。
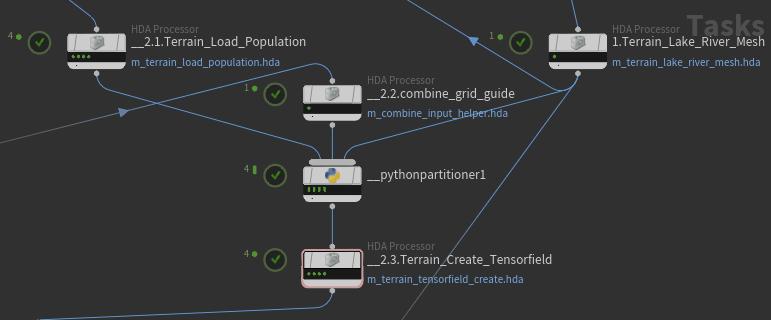
比如这里,最下面的HDA Processor需要连三个input,上面三个input分别有4,1,1个work item。
我希望下面HDA processor有4个work item,第i个对应上面的,i,1,1号work item.
只好自己写python partitioner。在partitioner中,work_items是输入的所有workitem,我们需要把他们加到partition_holder中。注意这个api,
partition_holder.addItemToPartition(workitem_i, index)
index是后面workitem的id,没有显式给出如何设定这个workitem_i成为下面workitem的几号input id,因为它把workitem_i设成了第index个workitem的下一个input。
1 | node_map = {} |
总之相当的绕
2. Cache与Dirty,粒度选择
每个HDA Processor会自动cache文件的。一般来讲,如果上游的文件dirt了或者重新生成了,下游的应该重新生成的。但是有时候,下游的直接去读cache了。。。。这样上游的修改就没进来。只能强行一个一个dirty and recook。有一个Workitem Generation的模式选择,感觉static就是只能手动重新生成,dynamic是每次下游一cook都自动cook一遍,笔者也并没太绕清楚。。。。
因为有可能有会有dirty不到的问题,笔者建议PDG中的HDA越少越好,粒度要达到一组输入一个HDA,不要为了重用做太多HDA。如果太多的话哪个一没dirty后面就全坏了,笔者最后才意识到这个问题然而为时已晚。
3. HEngineData
这个好像只跟HEU有关,可以看HEU_PDGObjects.cs中的TOPNodeTags定义。
用这个原因是
- 不然的话TOP中所有节点都会显示在unity中,很乱
- 不然的话,PDG一次只cook一个东西出来,会想让它自动加载一些东西。
使用方法是top中的节点自定义加一个string类型的henginedata,填show就是unity能看到,填show,autoload就是能看到且能自动加载。HEU会加载时自动读到这个参数的。

至于有关项目的一些原理:
道路
主要是这篇文章使用的技术,用tensorfield创建道路。
http://ma-yidong.com/2018/08/17/procedural-street-modelling-in-houdini-1/
需要输入的是
- population mask,人密度图
- seed points,一些产生道路的点,一般不用太多
- Grid guide,用于生成方格网络的引导线

地块:
主要是这篇的技术
http://ma-yidong.com/2018/08/29/procedural-parcel-modelling-in-houdini/

小别墅
这里用了L-sys生成基底


Disclaimer:
- 供个人学习,限于Houdini Engine没有non-commercial版本,所有资源并不开源,如需文件请联系笔者,如果喜欢请打个赏:)