Vibe Coding
今年写代码的工作模式已经变成主要靠 Agent 来辅助完成了。
去年还在和 AI 通过聊天框对话生成代码,到了今年,笔者开发时已经重度依赖 AI 代码 IDE 工具了。这一方面得益于大模型本身的能力提升,另一方面也离不开 Agent 技术的进步。前半年主要用的是 Cursor,后来因为没法使用 Claude,就换成了 Trae 一直用到现在。虽说 Trae 在能力上还有些不足,比如相比 cursor 没有原生的计划模式,但应对大部分开发任务已经足够了。尤其是今年做前后端项目时,用 AI 代码 IDE 特别顺畅,工作流大概:先让 Agent 生成文档,笔者审核通过后,再让 AI 搭建项目框架,之后具体功能开发就用 AI 做单元测试驱动开发。到了年底,发现用 Supabase + NextJS 这套技术栈时,发现体验尤其好 ——Trae 的 SOLO 模式还集成了 Supabase 的工具,能自动创建和更新数据库,省了不少事。
Coding & Agent
为什么写代码的 Agent 是目前 AI 最擅长的领域?我个人觉得主要有三个原因:一是工具使用能形成闭环,二是强化学习时的 Reward(奖励)定义很明确,三是涉及的模态很少。
先说说工具闭环。Agent 能否高效执行工具并获取反馈,直接影响它的实际能力。从年初的 MCP 到年末的 Skills,很多技术方案都在尝试开放平台来解决这个问题。对 Agent 来说,能自己构建 “自主收集信息 - 接收反馈 - 迭代优化” 的完整闭环( ReAct 框架)特别重要 —— 比如 AI 可以通过命令行调用工具编译、执行、测试代码,还能直接看到输出结果,再根据结果调整任务。不过有意思的是,可能 MCP 的开发者比实际使用者还多,而且行业内对 “工具使用是否能增强 Agent 能力” 这件事,至今也没有统一结论,只能再等等看后续行业进展了。
再看 Reward 的问题。强化学习(RL)的核心瓶颈,其实是 “怎么定义一个能落地的 Reward”。Reward 是 Agent 迭代优化的方向,如果缺乏客观、精准的 Reward,没法形成有效的迭代闭环。很多时候,Reward 必须靠人类来定义,但也有少数场景,Reward 的定义本身就很清晰 —— 比如代码执行结果对不对、测试通没通过、数学推理准不准确、UI 点击有没有命中。正是这些定义明确的场景,LLM 在后训练中才能做得比较好。这让我想到了定 OKR 或 KPI:短期可测量的 KPI 很适合当 Reward 来训练,但人类世界里,不是所有工作都能这么定量描述,甚至很多指标的反馈周期特别长,用来做训练基本没意义。人类的做法是开公司、筛选有共同目标的人来定 OKR,这本质是 “筛选” 而非 “训练”,那 Agent 的训练,会不会也需要类似 “自然选择” 的逻辑呢?
最后是模态问题。虽然现在很多大模型能理解图片、生成视频,也有能玩游戏的大模型,但和人类的多模态能力比起来,差距还很大。目前来看,以文本为主要输出的场景,AI 的完成度最高;其他模态的训练数据,其实还少得可怜。比如判断一款游戏好不好玩,不只是看文字描述或视觉效果,还涉及身体感受、神经反馈这些维度,这其实也是多模态的一种体现,但目前 AI 还很难覆盖到。
年度游戏
虽说笔者在游戏行业工作多年,但有点惭愧的是,直到今年才真正开始 “体会” 玩法设计的门道。
今年一共玩了 40 多款游戏,其中投入时间最多的是《远征队 33》《逃离鸭科夫》和《Megabonk》。口味倒挺稳定:还是不太喜欢 PVP 和强联机类的游戏;不过意外的是,今年几乎没碰策略和竞速类,反而又把 RPG 当成了主要类型。按品类分,《远征队 33》是 JRPG,《逃离鸭科夫》是 “搜打撤” 类型,《Megabonk》则是 “吸血鬼 like”—— 这三个品类我过去几乎没深入玩过,但今年却在它们身上花了很多时间,也因此更清楚地看到了它们各自 “独特的点” 到底是什么。
远征队33(JRPG)
《远征队 33》最突出的优势是 “美术统治力”,尤其是音乐和画面一起营造出的 “印象派” 氛围 —— 它不靠写实细节取胜,而是用色块、光影和旋律,把情绪直接传递给玩家。很多玩家都有个共识:只要你能 get 到它的审美,就很难不被吸引;也有人说它是今年少见的 “靠视听驱动叙事” 的 JRPG。对我来说,这个优势足够掩盖其他方面的瑕疵,带来一种 “眼前一亮” 的初体验。
网上讨论最多的机制,是它 “即时回合制 / 混合战斗” 的创新。很多人说这种设计让回合制更有动感和张力,但我更认同另一种观点:它更多是在视觉和节奏上做了升级,而非让策略深度产生质变。确实,这种战斗方式更好看、更有冲击力,让回合制不再那么 “站桩”,但核心乐趣还是 JRPG 那套 —— 队伍构筑、资源管理和节奏控制。叙事方面则评价两极:主角团的 “类型化塑造”,对喜欢传统 JRPG 的玩家很友好,但讨厌的人会觉得套路化,或者情绪推动太刻意;不过这不算致命问题,单靠它的视听表现,就已经值得一玩了。
逃离鸭科夫(搜打撤 / 轻量塔科夫式)
《逃离鸭科夫》最聪明的地方,是把 “搜打撤” 的紧张感做了 “降门槛” 处理。它保留了 “撤离” 这个核心闭环(生存下来、带出资源、再投入下一局),同时用更轻松的节奏、更明确的成长线,把硬核的 “搜打撤” 拉向了更大众的 “RPG 化刷装” 体验。网上对它的好评,大多集中在 “容易上手”“不容易被挫败感劝退”“单局压力可控” 上,甚至有人把它当成 “搜打撤入门教材”。
同时,它也用了很多 “经典 RPG 逻辑” 来增强玩家黏性:角色成长、解锁新内容、任务叙事、逐步变强的确定性回报 —— 就算不喜欢高对抗,玩家也能从 “稳定推进进度” 中获得持续动力。这一点对我这种不爱 PVP 的人来说很关键:它让 “搜打撤” 不再只依赖 “和人斗的乐趣”,而是靠 “今天又多进步了一点” 的安全感留住人。当然争议也有:对硬核 “搜打撤” 玩家来说,它可能不够残酷、不够 “真实”;而且到了中后期,内容重复、最优解趋同,加上掉落率、经济系统、武器手感的平衡调整,也经常成为玩家讨论的焦点。
Megabonk(吸血鬼like / 幸存者类 3D化)
《Megabonk》的独特性,在于把 “吸血鬼 like” 的核心循环(快速构筑技能、海量击杀敌人、短周期反馈)做成了真正的 3D 空间体验。过去很多玩家觉得这类游戏用 2D 俯视视角就够了,因为核心爽点在数值和清屏;但《Megabonk》偏要反着来 —— 加一个维度,把移动和空间策略拉进来:跳跃、爬墙、走位、闪避,让 “躲弹幕、拉怪、控场” 从 “平面几何” 变成了 “立体路线规划”。网上常见的好评是 “像把幸存者类和动作 RPG 的手感拼在了一起”,这种差异化在同类游戏里很容易让人记住。
当然,为了支撑 “海量敌人” 的玩法,它也做了明显取舍:画面资源和敌群表现更服务于玩法,而非观赏 —— 敌人动画帧率偏低,同屏信息密度大时,清晰度和性能也会打折,这是玩家常吐槽的点。另一个常见批评是 “构筑爽但容易滚雪球”:一旦抓到强势技能组合,中后段就会从 “紧张对抗” 变成 “碾压清场”,需要更多模式或数值调校来支撑长线体验。不过就即时体验来说,这种 “快速变强、快速看到结果” 的快节奏成长,正是它让人一局接一局停不下来的原因。
游戏开发
今年笔者写了不少关于游戏未来的博客,很多内容都和 AI 创作相关,这里就不一一展开了,只贴出几篇的摘要,方便大家快速了解核心观点。
这篇文章聚焦于 AI 如何重塑游戏的三个核心要素:状态、行为空间与表征。AI 让 “状态” 从单纯的数值(比如血量、金币),变成了记忆链、向量等复杂系统;让 “行为空间” 从开发者预设的动作集合,走向动态开放(比如自由输入指令、任意肢体反馈);让 “表征”(玩家感知世界的媒介)从提前制作的美术资源,变成实时生成(比如随情境变化的树木形态、NPC 语气)。文章还强调,游戏的本质不是 “复刻现实”,而是对现实的 “艺术化切片”—— 提取核心体验,用可控框架浓缩成交互内容。AI 的价值不是追求 “无限自由”,而是在创新与可控间找平衡,让 “切片” 更精准、体验更普适。最后,文章预测了 AI 游戏的四个演进阶段:从 AIGC 工具辅助制作,到 AI Agent 优化行为空间,再到 AI NPC 与 VR 融合的混合世界,最终到脑机接口支撑的全沉浸体验,核心都是让游戏的 “可控沉浸” 更灵活。
这篇文章围绕 “顶点块下降(VBD)” 这种新型物理模拟方法展开,探讨它在 GPU 物理引擎中的应用潜力。VBD类方法通过能量下降迭代和局部解算,相比传统物理引擎在收敛速度和并行性能上具有显著优势,特别适合GPU计算。然而,当前GPU物理引擎在游戏应用中面临CPU/GPU数据同步延迟的挑战,影响了触发器和碰撞反馈等交互逻辑。文章提出了混合模式和全GPU驱动两种架构方案,指出该技术目前最适合大规模物理模拟或体素类游戏,但因开发难度和生态不成熟,尚未成为主流通用方案。
3D Gaussian Splatting:影视与游戏领域的应用分析
这篇文章分析了 3D 高斯溅射(3DGS)技术在影视和游戏领域的应用前景。在影视行业,3DGS 有望重构制作流程:靠后期编辑能力简化前期布景和妆造,还能催生两类商业机会 —— 一是商用空间光场拍摄设备,二是 AIGC 驱动的后期工具。。在游戏领域,尽管目前面临移动端效率、动态光影及物理交互等瓶颈,但 3DGS 相比纯视频生成具有显著的渲染成本优势。作为混合渲染管线的一部分,它在 AIGC 资产生成、复杂几何(如植被、云雾)的高效表示以及高保真角色还原方面展现出巨大潜力,将推动视觉创作向更高效、沉浸的方向演进。
这篇文章探讨了游戏 “破坏效果” 中物理模拟与艺术表现的关系,核心观点是:好的破坏效果不是 “越真实越好”,而是 “物理真实 + 艺术规则 + 玩法需求” 的平衡。文章用四个案例做了分析:《Control》靠 “层次化预制碎片”和程序化工具,让传统刚体物理呈现出强视觉冲击;《Instruments of Destruction》用规则驱动坍塌,在 Unity+PhysX 框架下做出了策略性拆楼体验;《BeamNG》的车辆软体模拟虽在物理真实上做到极致,但缺乏艺术化补充;《Teardown》则用体素技术 +“艺术化破坏规则”,让破坏融入关卡设计,牺牲部分物理严谨性换来了更强的表现力。结论是,优秀的破坏系统并非单纯复制现实物理,而是“物理真实 + 艺术规则 + 玩法需求”的平衡产物,旨在服务于游戏体验。
做的游戏
今年笔者做的两个游戏项目上线(Demo,EA)了,不过都还有不少待完善的地方。
第一个是 “风洞模拟器”。核心功能是用 CSG 建模拼出一个模型,然后通过风洞模拟吹它,得到各种数据和可视化结果。但笔者一直有点纠结它的定位:作为解谜游戏,虽然做了两个关卡,但后续很难拓展,也没有完整的游戏循环;作为可视化工具,计算结果又不够精准;作为沙盒游戏,可交互性太差;或许它更像一个技术 demo,用来证明风洞模拟能实时可视化运行。
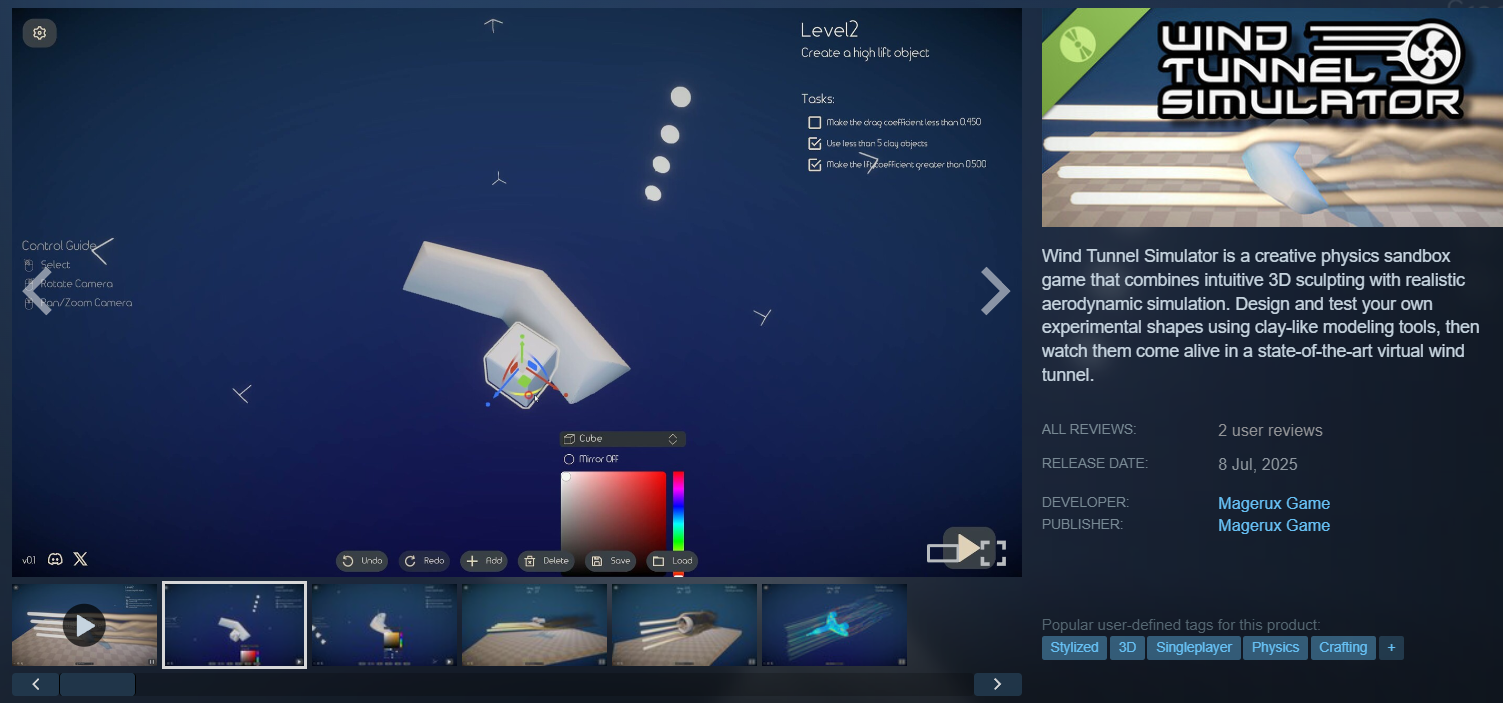
技术上,用 Lattice Boltzmann 方法通过 Compute Shader 实现 —— 这套方法本身是符合物理规律的,虽然没做可移动边界和多介质模拟,但计算结果至少在定性上是对的。开发时遇到的最大问题,就是 “物理太写实” 反而限制了玩法设计:用模块拼装模型时,很难做出让玩家有成就感的成长体验。很多 RPG、模拟经营游戏,看似是视觉化体验,核心其实是数值成长 —— 数值和成就的提升驱动玩家持续玩下去;就算是有组装玩法的赛车游戏,本质也是设计师构建的数值体系在起作用。可一旦游戏太依赖物理真实,数值成长的空间就被压缩了;如果做解谜玩法,又很难设计出一套合理的谜题体系,或许这类项目只能走沙盒路线。
第二个是 Voxel Playground,一款类似《Teardown》的体素 VR 游戏,目前在 Meta Quest 平台发售。用 Unity 开发。刚上线的版本有沙盒 Mod 玩法和生存玩法,笔者主要负责体素物理、破坏系统和渲染部分。体素物理参考了《Teardown》的设计,真的做了体素级碰撞;渲染上加了简单的昼夜循环和 LPV 光照;破坏系统则大量用了 Job 并行来优化性能。最后能在 Quest3 上完整跑通一个小规模场景,已经很不容易了。这开发让笔者体会到:一个技术要在业务场景里落地,比做 demo 复杂多了 —— 要考虑性能、要平滑重构迁移、要考虑同事的开发体验,还要兼顾玩法体验的特殊需求。
其实这两个游戏的问题在《Teardown》中也存在:因为用了真实的物理系统,很难加数值成长体系,门槛相对较高,可能没法让大多数玩家觉得 “好玩”。《Teardown》除了沙盒模式,在真实物理引擎上只能做 “拆迁 + 撤离” 的解谜玩法,我个人就很难沉浸到这类关卡里。
网球
笔者打网球也快 8 年了,但之前感觉都是随便玩玩,直到今年才真正开始参加比赛。年初先打了些非正式比赛,打磨技术和心态;年中参加了 Tennis123 的 2.5 单打比赛,四胜一负拿了冠军,直接升到 3.0;到了年末,打 2.5-3.0 级别的双打,也能起到 “carry” 的作用了。说实话,到了这个年纪,身体素质很难有质的提升,技术和球感还有进步空间,但心态是最容易提升的部分。
今年学到一个冷知识:费德勒职业生涯的胜率是 80%,但每一分的得分率其实只有 54%—— 原来顶尖高手也不是每一分都能赢啊。其实就算是大满贯比赛,选手之间的差距也没那么大。
参加的那场 2.5 单打比赛,过程还挺曲折的:小组赛第一场放不开,输了;后面两场调整了状态,都是 4:0 拿下;半决赛遇到个 “大磨王”,最后把他心态打崩了,抢七局打了个 7:0;决赛则复仇了第一场输给的对手。这段经历让我总结出两点心态上的关键:一是 “平常心”,上一个球的结果不重要,每一分都要忘记比分,当成第一个球来打 —— 尤其是发二发的时候,这样才能避免紧张导致动作变形;二是 “专注”,要像狩猎一样集中注意力,甚至可以调动一点愤怒的情绪来让自己更投入,只有眼里只盯着球,才能打出稳定的击球。
打球是这样,人生其实也差不多。遇到实力远超自己的对手,承认差距就好;但大多数时候,对手和自己实力相当,机会并不少,关键是别慌了心态。好的心态,往往能让表现提升一大截。
==分割线==
以上,作为年终总结,
最后,祝各位读者新年诸事顺遂!