TLDR;
- 游戏中的美术资产有严格的性能限制,因此存在许多传统的美术制作技术。目前,Text to 3D的效果与人工制作的质量存在显著的差距。
- 公开数据集提供的三维模型数量有限,未来难以有大幅度提升。
- 个人对Text to 3D在当前游戏领域的直接应用持悲观态度,但期待其在其他领域的应用和发展。
目前,Text To 3D技术已经引起了广泛关注。Luma AI Genie等产品已经能够生成外观质量不错的三维模型,引发了大众的期待和担忧。本文主要探讨当前Text to 3D技术的不足以及未来的发展方向。
Text To Image 的启示
Text to Image技术的迅速发展给我们提供了宝贵的启示。从2022年末Stable Diffusion发布至今,短短一年半的时间,它已经席卷了传统2D图像生成的多个领域,如插画、营销视觉设计、影视游戏概念设计等。高级艺术家借此更快实现创意,而初级设计师则面临生存困境。与此同时,更多原本与设计师协作的职业现在可以使用MJ等工具自行生产素材。在游戏领域,《世界之外》等乙女游戏通过提升物料生产力,显著提高了游戏体验。这让我们不禁思考,相似的情况是否会在三维领域上演?
30 FPS 的限制
大多数游戏需要至少维持30帧每秒(FPS)的渲染速度,这对场景设计和美术资产的制作构成了显著挑战。
在光栅化技术盛行的时代,实时渲染三维场景时,面数成为了一个重要的技术瓶颈。一般而言,移动设备能够处理的同屏面数约为30万,而桌面端则能达到300万左右。相比之下,浏览器环境下的渲染能力可能还要低一个数量级。对于VR一体机来说,性能限制更为严格,如Quest 3上的游戏场景复杂度大致相当于十年前的手机游戏。
尽管光栅化技术在过去二十年中一直占据主导地位,但最近也出现了一些突破性的新技术。例如,三年前出现的Nanite技术通过通用计算来替代部分光栅化计算;五年前问世的硬件光追技术则直接采用光线追踪来取代光栅化计算。然而,这些新技术目前大多仍处于高端领域,看似在短期内难以撼动光栅化的主流地位。
除了光栅化的限制外,内存也是另一个关键因素。以手机为例,其内存使用通常限制在500MB至1GB范围内,其中分配给贴图的内存更是有限,仅有几百MB。这导致资产的面数和贴图尺寸都不能过大,从而催生了一系列传统的三维制作技巧。
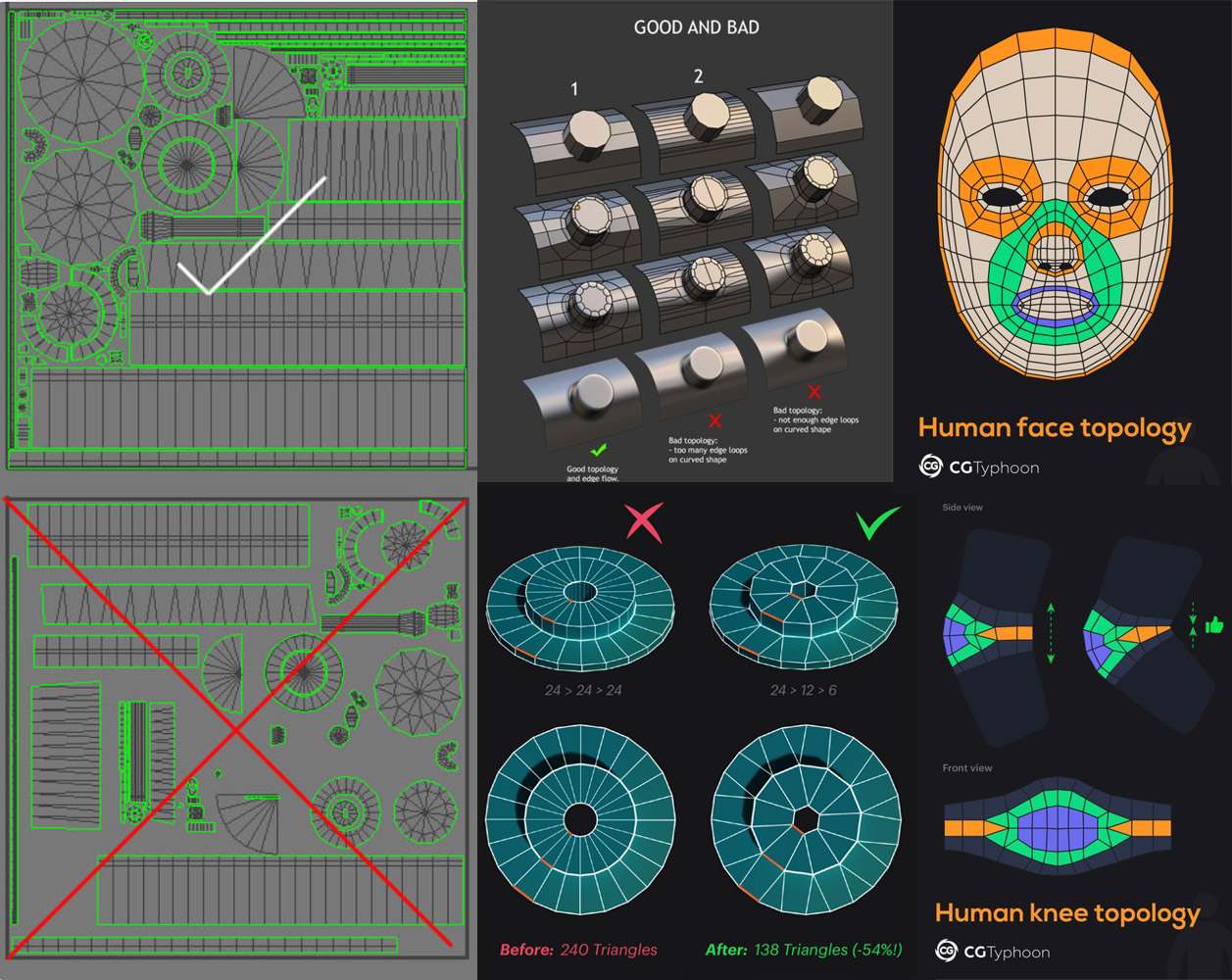
游戏需要在性能和质量之间找到平衡点。因此,在游戏美术资产制作过程中,一个核心矛盾就是如何在较低的面数和较小的贴图尺寸下实现逼真的效果。这在以三维为重点的游戏类型中尤为重要。传统制作流程中,为了提升场景表现力并解决面数限制问题,涌现出了诸如模型布线、法线贴图和UV重用等技巧。
模型布线通过优化三维模型顶点的排列方式,使得用更少的顶点和面数就能表现出原有的形状;法线贴图则利用纹理计算让面数较少的三维模型呈现出更高清晰度的效果;而UV重用则通过最大限度地重用贴图资源,在有限的显存和带宽下实现更好的显示效果。
在主打内容体验的游戏中(如RPG游戏),画面中物体的数量和质量对沉浸感至关重要。因此,这类游戏对美术资产的性价比有着极高的要求,也培养出了一大批专业的游戏三维美术从业者。
不同类型的资产对布线的需求也不尽相同。例如,硬表面模型(如载具和枪械)通常使用较低的面数,布线主要为了勾勒出轮廓,并严重依赖法线贴图来表现倒角细节;植物模型则更倾向于采用“插片”的制作方式;而角色模型的布线则需要考虑骨骼旋转方向等因素。无论哪种类型的模型,都希望通过重用UV来减小贴图的尺寸,从而提高渲染效率。
目前 Text To 3D 的缺陷
尽管Text To 3D技术已经取得了一定的进展,但生成的资产在面数、布线和UV质量等方面仍远不及专业游戏美术手工制作的水平。以我自己制作的道具资产为例,直接生成的面数可能比手工建模多出十倍,UV布置无法重用,也可能导致贴图数量增加四到十六倍。这对于性能要求极高的游戏领域来说,是一个难以接受的缺陷。

当然,不同类型的资产对布线的需求也不尽相同。硬表面模型如载具和枪械对面数控制有严格要求,布线主要为了卡轮廓,并强烈依赖法线贴图表现倒角。植物等自然类资产对面数要求相对较低,Text to 3D技术在这些方面可能有一定的应用空间。角色类资产的布线在Text to 3D自动拓扑后可能更容易修复,因为传统流程中在ZBrush完成雕刻后也需要进行重拓扑和手工修复。
高质量模型数据问题
目前,模型的布线和UV制作仍然高度依赖手工操作,缺乏有效的一站式自动化解决方案。为了解决这个问题,我们可能需要转向采用数据驱动的方法。
尽管目前最大的模型数据集Objaverse-XL包含了1000万个三维物体,其中大部分来源于Sketchfab和Thingiverse,但这些模型对于布线和UV的要求并不高。例如,Thingiverse主要面向3D打印模型,以及其他一些扫描模型,它们并不适用于游戏开发。在这些数据集中,真正与游戏相关的模型可能仅限于Sketchfab上的约80万个。然而,这些模型中能够达到游戏标准的数量仍然是一个疑问。事实上,游戏开发通常不会直接使用Sketchfab模型,最多在概念阶段加以参考。
高质量的图片和视频数据在互联网上有丰富的展示资源,但三维模型并非如此。例如,艺术家聚集的ArtStation平台虽然提供了大量图片供免费查看,但分享的模型大多需要付费获取。此外,获取的资产还可能存在格式不兼容的问题。
如果想要让 AI 模型能够生成游戏可用的资产,第一步肯定是收集游戏中目前使用的资产。
要让AI模型生成适用于游戏的资产,首先需要收集游戏中目前使用的资产数据。一种可能的方法是从Unity或UE应用商店获取付费资产。这些资产在引擎内部的表示相对统一,便于数据清洗。以Unity Asset Store为例,在线总共1万个资产包,按每个资产包20个模型计算,可以获得约20万个模型的数据量,接近Objaverse数据的数量级。然而,这些资产同样存在质量参差不齐的问题。
另一种方法是通过逆向工程获取游戏中的资产。假设Steam上有5000款3D游戏,每款游戏有100个资产,那么可以获得约50万个模型的数据量。然而,逆向工程一来技术上并不是一件复制的事情,二来存在法律和道德风险。
其他途径可能并不可行。例如,游戏厂商的自有资产通常闭源且难以获取。即使在大型游戏公司内部,也只能收集到有限数量的游戏资产。同时,资产与制作流水线密切相关,脱离游戏引擎可能无法直接使用。即使能够收集到这些资产,政治问题也可能成为阻碍因素。不同项目组之间可能存在竞争和自负盈亏的情况,难以共享资产。此外,外包商受到保密协议的限制,无法直接使用资产进行训练。
因此,从以上分析可以看出,真正适用于游戏模型生成的数据量可能不到100万个模型,这与以十亿计的图片视频数据相比显得相形见绌。
可能的出路
有没有可能,横空出世一种技术,能够在不依赖大量数据的情况下生成具有良好布线和UV的三维模型?
有没有可能,Text to 3D 的主要领域不是传统游戏?而是一些对于性能没那么敏感的应用场景,比如 MR中?或者有新的游戏类型出现,并不需要密集的三维资产场景,但其中 Text to 3D 又是很重要的玩法组成部分?
有没有可能,未来游戏的场景表示也可能发生变革。随着隐式表达形式如Nerf/3DGS等的发展,游戏场景可能不再需要多边形来表示。这将使得文生图片和文生视频技术能够直接应用于游戏场景生成中,同时扫描类资产也可以直接使用。去年出现的 “Bodycam” 这个 FPS 游戏可能就使用了类似 Nerf 的技术,因此笔者也很期待这方面的进展。另外,也许文生视频能达到比较高的性能,直接用 Sora 就能玩游戏?
总之,对于 Text to 3D 直接在目前的游戏领域的应用,个人表示悲观。但对于 Text to 3D 的其他应用,需要等待其他领域的成熟可能才能派上用场。