1 Post-Processing 到 Image to Image Translation 图片翻译
这次想做的是如何用神经网络来后处理。后处理是游戏中常见的一种图像效果,核心任务也就是把原始图片通过一些图片处理的手段,转化成另一种更好看的效果,常见的比如Bloom, LUT等等。而深度学习界最近出现的一个很热的话题就是图片翻译,如何从一张图片转化成另一张图片?
其实两者都是图片到图片的任务,但也有很大不同
- 通用性,后处理一般是精心设计的工程方法,适用于特定的任务;但是神经网络基本可以算是通用方法了,就目前来看几乎可以做任意domain图片的转化
- 性能,后处理对实时性要求很高,内存占用也不能太大。而神经网络没有个几GB的显存或者TPU就别想训练了。
本文这里是希望能否让通用性的神经网络以实时性能运行起来?

可以看演示的效果,在网络比较浅的情况下,30fps完全可以保证,不过可以接近目标效果的色调,但是很难重现其笔触。
实际上本例笔者制作了监督学习的训练集,制作方法是:
- 截取原始场景大量截图
- 使用Photoshop动作批量进行风格化处理
- 使用这些成对数据训练pix2pix
- 训练好的模型在Unity中作为后处理实时运算。
2 Image to Image Translation 图片翻译
近年来深度学习的一个常见问题,如何从一张图片生成另一张图片?
NST
比较早相关的是一篇Neural Style Transfer的文章(Gatys, 2016),核心原理可以理解成,找到原始图片与目标图片的平均值,这个距离值用神经网络激活层的一个函数定义,并通过神经网络反向传播梯度求解,
%!(EXTRA markdown.ResourceType=, string=, string=)
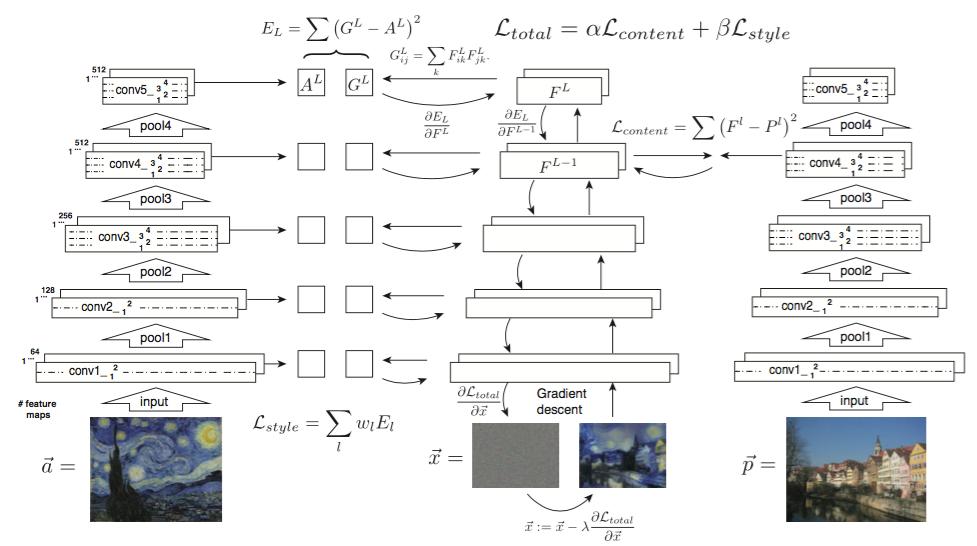
下图是其基本原理,风格图片与生成图片的激活层的格拉姆矩阵即L-style,目标图片与生成图片某个激活层的方差,即L-content,目的是用L-style + L-content作为目标函数梯度下降求解
Pix2Pix
15年提出的Generative Adversarial Network(GAN)最开始被用来从随机向量(latent space vector)生成图片,具体原理这里不再细说,它衍生出了一个叫Pix2Pix的东西。
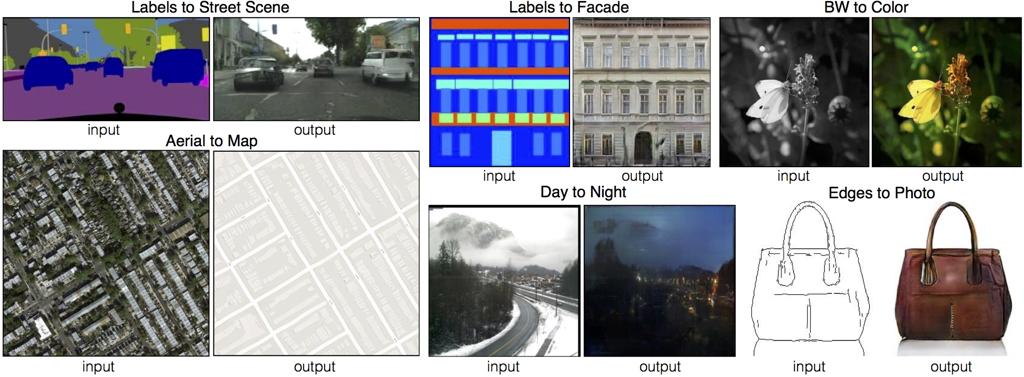
与原始GAN不同主要在于Generator变成了张量到张量。它是监督学习的方法,需要提供一些成对数据的训练集,训练之后就可以进行图像翻译的任务了。
之后衍生出了Pix2PixHD。要点在于Pix2Pix可以生成的图片很小,一般是256256的,而Pix2PixHD可以生成20481024的街景图片。
keijiro把Pix2Pix的sketch2cat模型搬到了Unity,可以实时画猫
%!(EXTRA markdown.ResourceType=, string=, string=)
另外一个Pix2PixCity的项目,程序式生成城市简模,利用pix2pix街景的训练模型生成城市的视频

CycleGan/DualGan/DiscoGan
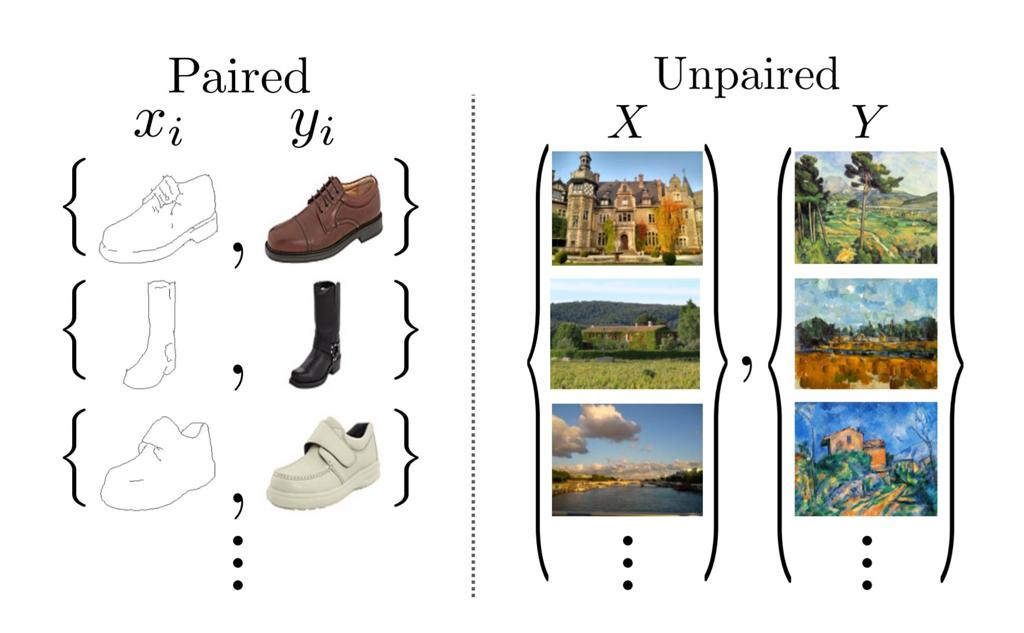
后来又衍生出了CycleGan/DualGan/DiscoGan,与PIX2PIX不同的是,这三个非常相似的结构都是非监督学习的,也就是给它非成对的图片数据,它也可以进行图片翻译的任务。
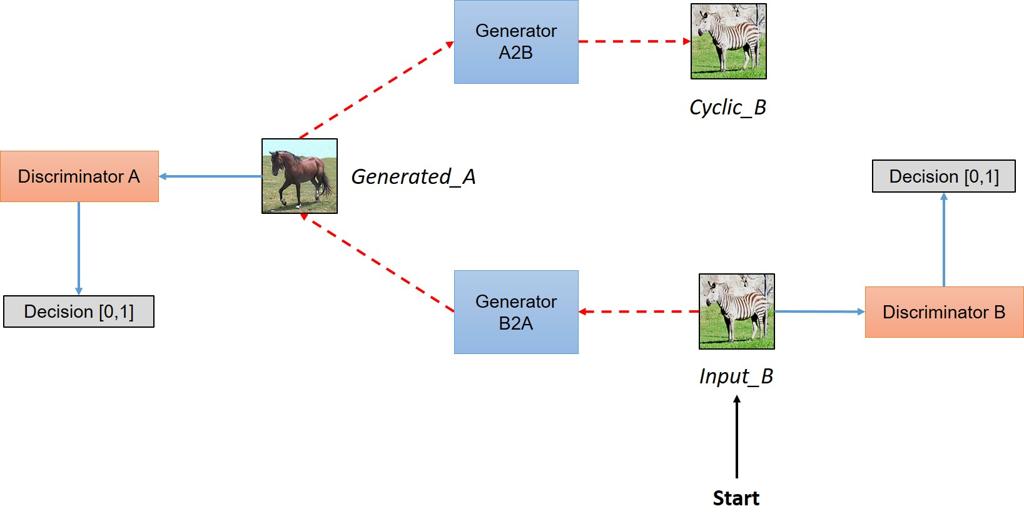
核心思路是通过两个成对的Generator/Discriminator进行训练,从图片A到图片B,从图片B到图片A
可以将图片理解为一个数据概率分布,这就比较好理解NST和GAN的区别。NST目的是寻找两个数据分布之间的中间值,而GAN的目标是实现两个数据分布之间的转化。在NST中,目标数据分布之间的距离是一个人工构造的函数,即激活层的一些方差格拉姆矩阵等运算。而GAN中,数据分布的距离是Discriminator拟合出来的,理论上讲可以到达一些理论距离比如JSDivergence等等。
3 Implementation 如何实现
模型的训练直接使用了KerasGAN中pix2pix的源码,不同的是原始pix2pix的Generator非常复杂,为了提高运行时性能,训练时减少了网络的深度,比如这样一个网络在运行时是基本没问题的,但是效果只能说勉强可以接受。
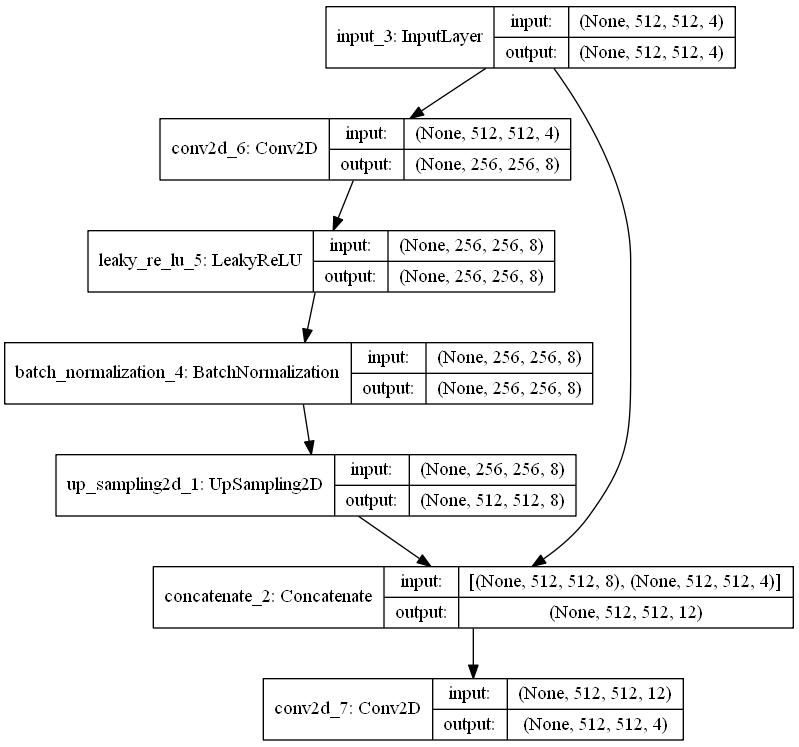
训练数据生成时考虑了深度通道,因此与keras-GAN上不太一样,笔者这里一个成对数据长成

运行时为了减少依赖,完全采用ComputeShader实现神经网络卷积等运算。参考了keijiro的实现,比如卷积运算,强调memory coalesce的思想,每个threadgroup读取数据到cache中,同步数据后再下一步运算
1 | //each kernel x |
也进行了一些改进,keijiro实现中在线程数很少的情况下表现比较差,因为一个warp就32个线程没法再少了,只能多用点cache,多几个texel同时做卷积了。
4 未来如何?
当前来看硬件还是不太足以支持任意的实时图像翻译,理想中未来的风格化渲染工作流程完全可以是:
- 标准光照模型进行渲染
- 使用目标风格的图片进行非监督训练(Cycle Gan) 或者 原画在标准光照模型上进行绘制,制作训练集
- 通过训练集训练神经网络
- 客户端部署训练好的神经网络
甚至有可能完全使用神经网络做渲染,目前pix2pix的输入标记图片很像材质id图,但是实时渲染不仅有这个信息,还有深度法线等很多数据。因此有可能
- 通过游戏中的画面训练一个模型,输入材质id,法线等,生成渲染效果
- 游戏制作中只需要制作简模即可
- 运行时只渲染建模的id,法线等,直接通过神经网络生成渲染效果。
这样的话实时渲染的光照模型hack也就一点用没有了,毕竟训练集可以完全离线渲染,只要有神经网络就好了。
但是前提是显卡的计算量极端充裕,因为这相比于后处理可能需要更加复杂的模型。想要实时运行起来就目前来看还很遥远。
Reference
Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 2414-2423.
https://phillipi.github.io/pix2pix/
https://github.com/NVIDIA/pix2pixHD
https://tcwang0509.github.io/pix2pixHD/
https://github.com/keijiro/Pix2Pix