目前主流的OC有这几种方式:预计算的原始的PVS,主要CPU端的umbra的dPVS。和主要GPU端的GPU-Driven。像RealTimeRendering中提到的Hierarchical Z-Buffering和HOM,大多比较底层,集成在其它实现方案里,比如dPVS用了HOM的技术。
1. 简单PVS
直接离线计算每个位置上的可见物体集。位置用cell描述,几米一个。给每个物体一个ID,存一个bitarray记录可见性,内存占用也很小。实时运行很快,只是离线计算比较慢,在手游上很容易实现。有几个要点:1. Cell划分,最简单的就是平均切分了,更细致的考虑还有按密度自适应cell大小(比如四叉树),高度上可能有多层需要支持等等。2. 可视性计算,从Cell到被判断的物体,采集哪些射线求交并且速度快就有学问了。最简单的是直接格子和被判断物体的AABB间连线,这是非常保守的了。3. Streaming,开放世界做streaming的话,物体ID就得按chunk给了,可见性bitarray同样。
不过PVS似乎在Asset Store上没有现成的做法。但是自己写一个也是很快,而且效果不错。唯一问题就是听起来技术比较low。据笔者所知,盘古和互娱的手游都有开发自己的PVS系统。内部资料就不分享了。
2. dPVS
Unity自己的Occulusion Culling用的是Umbra的中间件,也就是dPVS的技术。是Timo Aila提出的,当时是他在赫尔辛基大学的硕士毕业论文。后来他成立了Umbra,07年加入了NVIDIA Research. dPVS虽然叫PVS,但是和纯离线的原理有很大区别。它离线不计算所有可见性,而只是生成一个空间数据结构,一个BSP描述的节点信息,用于之后的空间位置查询。因此离线计算的速度快很多。但是在线会多计算不少东西,包括跟踪可见物体的标记点,提取轮廓生成HOM等。
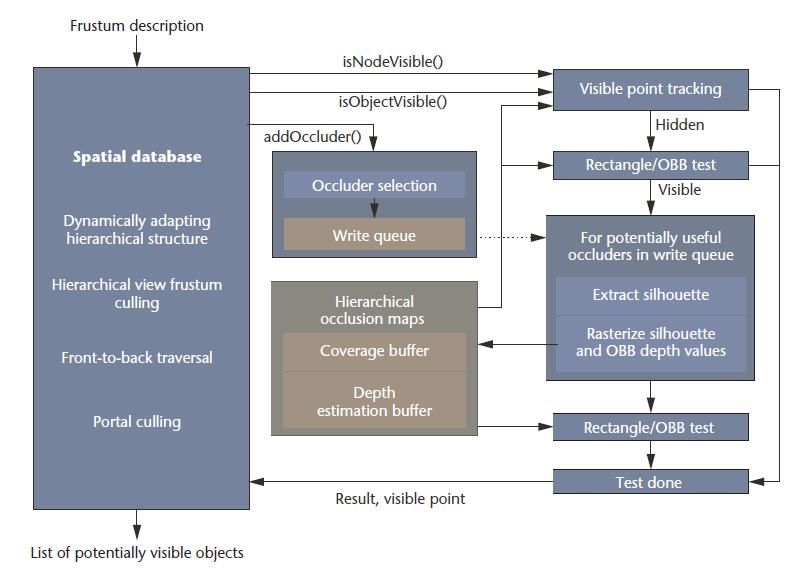
dPVS的提出在2000年,借鉴了hierarchical occlusion maps的技术。创新有两点:一是Occulusion Map的计算用提取轮廓的方法。二是剔除前做visible point tracking,cache一些可见物体,可见的就不参与计算了。
其中visible point tracking如图,可见的就不再参与下面的遮挡计算了。
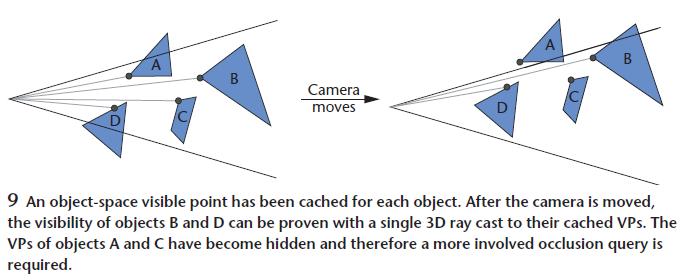
提取轮廓线的计算比较精妙,比渲染所有三角获得轮廓的做法快不少。思想就是缓存轮廓边,有需要再更新。算法里会缓存轮廓边和轮廓边邻面所在平面到视点的距离,如果邻面平面到视点的两个距离都是正的,那肯定就是轮廓了。如果有一个变负了,再去找相邻的边有没有成为轮廓边。用法线点积运算计算。
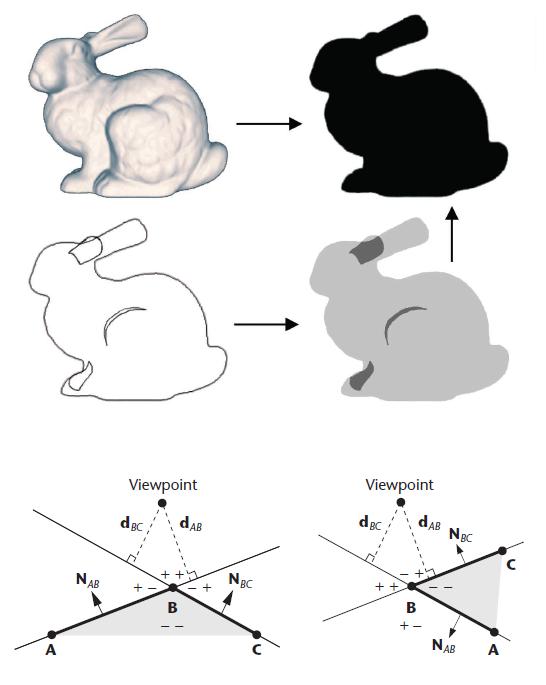
第一个pass找到轮廓边并光栅化后,用第二个pass填充区域。初始是左边1,右边-1;第二个pass一列列扫过去就行了,全都是位运算。
看上去很酷炫,烘焙速度很快,unity自带。唯一的问题是在手游上CPU的性能开销还是可观的,一帧1-2ms不成问题,比原始PVS高一个数量级。另外不支持streaming,这样大场景的内存占用是不太能接受的。
3. GPU Driven
这种就比较叼了,全部用compute shader做遮挡剔除,然后用compute shader来合并index/vertex buffer。结合Virtual Texturing和DrawInstanceIndirect,简直可以一两个drawcall画出所有的场景。
参考
[Siggraph15] GPU-Driven Rendering Pipelines https://zhuanlan.zhihu.com/p/33881505
[GDC16] Optimizing the Graphics Pipeline with Compute https://zhuanlan.zhihu.com/p/33881861
https://en.wikipedia.org/wiki/Potentially_visible_set
Aila, T., & Miettinen, V. (2004). Dpvs: an occlusion culling system for massive dynamic environments. IEEE Comput Graph Appl, 24(2), 86-97.